共计 1320 个字符,预计需要花费 4 分钟才能阅读完成。
在MSA手册中有两个概念,有的学员不理解。一个是分辨力(Discrimination),另一个是有效解析度(Effective resolution)。其实简单地说分辨力是指测量设备可分辨读数的最小单位,也称为最小可读单位、测量解析度。而有效解析度则是指测量系统的分辨力。测量系统的分辨力必须考虑测量系统的重复性和再现性。
问题:一个测量系统中所用的测量设备是最小可读单位为0.02mm的卡尺,用这个测量系统能否分辨10.00mm和10.02mm这两个尺寸?
答案是否定的。这个测量系统中的测量设备(卡尺)的最小可读单位为0.02mm,也就是说卡尺的分辨力为0.02mm。但这个卡尺所构成的测量系统的有效解析度,即这个测量系统的分辨力是否能达到0.02mm还需要考虑该测量系统的重复性和再现性。由于测量系统存在重复性和再现性误差,因此,一般情况下,测量系统的分辨力(也就是有效解析度)都小于测量设备的分辨力,所以尽管测量设备(卡尺)的分辨力可为0.02mm,由该卡尺组成的测量系统是不能分辨出10.00mm和10.02mm这两个尺寸的。
现在让我们了解测量系统的分辨力(也就是有效解析度)是如何确定的。
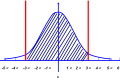
假设已经知道一个测量系统的偏倚为B,重复性和再现性标准差为σm,则采用这个测量系统对一个零件的特性进行多次测量,其测量值X服从均值为XT+B,方差为σm2的正态分布,其中XT是零件特性的基准值,见下图:


为分析发生这种错误分类的概率,现在构建一个新的随机变量XN,XN=X1-X2。显然XN也服从正态分布,其均值μN= XT1+B–(XT2+B)= XT1– XT2,方差σN2=σm2+σm2=2σm2

当μN=3σN时,P=0.135%,错误分类概率很小。
也就是当![]() 时,把XT1和XT2相互错误分类的概率P=0.135%。
时,把XT1和XT2相互错误分类的概率P=0.135%。
一般把 ![]() 定义为测量系统的分辨力Δ,即:
定义为测量系统的分辨力Δ,即:![]()
测量系统分辨力的意义:当不同零件的被测特性之间的差别 ![]() 时,测量系统对它们错误分类的概率<=0.135%。
时,测量系统对它们错误分类的概率<=0.135%。
假定一个被测零件特性的基准值服从正态分布,方差为σp2,采用一个测量系统对这个特性进行测量。只有当这个测量系统能够可靠地把在零件间的变差(6σp)范围内的零件特性值分成5个或更多个数据组时,才能满足为进行统计过程控制而进行测量的要求。这就是测量系统分析中所谓“区别分类数ndc(number of distinct categories)”的概念。

文章来源:网络









 hello world
hello world
hello world
hello world
hello world
hello world
 大师兄
独立事件和卡方检验,都是非常重要的质量管理概念,挺难理解的。
大师兄
独立事件和卡方检验,都是非常重要的质量管理概念,挺难理解的。
 infinite cui
需求VDA6.3 表格,谢谢
infinite cui
需求VDA6.3 表格,谢谢
 john
如何获得这个PPT文件
john
如何获得这个PPT文件