共计 6014 个字符,预计需要花费 16 分钟才能阅读完成。
1. Cp, Cpk, Pp 和 Ppk概念
Cp, Cpk, Pp 和 Ppk都是用来体现过程能力的指标,它们是用来测量过程能力的指数(process capability index),不是过程能力本身。很多人只知道计算这些指数,却并不知道过程的固有能力到底是什么。那什么是过程能力(process capability)?
2. 过程能力的定义
过程能力是指过程本身在没有外因干预、没有漂移(drift)(即统计学意义上可控under statistical control)的情况下其产出品的均一程度 (uniformity of product)。不难理解,我们不可能直接测量过程本身,而只能通过测量其产出品的某个特性来体现其能力。通常用被测量的特性的离散程度, 即标准方差, (西格玛),来表示过程能力。而且过程能力被量化为 ,即其总宽度为6个西格玛。
例如A过程的西格玛=2,其过程能力=6*2=12。
B过程的西格玛=2.5,其过程能力=6*2.5=15。那么问题来啦:A过程和B过程那个好呢?
答案是:视情况而定(it depends)。为什么?因为没有判断标准。
3. 衡量过程能力的指标的定义与计算公式
也许你已经注意到过程能力的定义与产品的可接受标准(specifications)无关。可是抛开产品的可接受标准,单纯地讲过程能力,又毫无意义。这就是为什么人们要引入“过程能力的指标(Cp, Cpk, Pp 和 Ppk )”这些概念。
Cp, Cpk, Pp 和 Ppk这些指数是过程能力和可接受标准比较的结果,也被称为过程能力比率(process capability ratio)。笔者更倾向于使用过程能力比率,因为它直观。另外这些概念的计算都引入了标准方差或西格玛,因此它们都是统计学意义上的概念,也正是如此它们都没有单位。
有趣的是,权威书籍中均没有体现这几个符号(Cp, Cpk, Pp ,Ppk)所代表的英文词。而在这个英文网站上⑥:https://www.isixsigma.com/tools-templates/capability-indices-process-capability/ 有以下的定义:
")
这些定义很显然是有问题的,因为这四个符号都是“index”或“ratio”。笔者认为它们的定义是这样的:
Cp= Process Capability Ratio 可被译为“过程能力指数”
Cpk= Process Capability K Ratio 可被译为“过程能力K指数”
Pp= Process Performance Ratio 可被译为“过程绩效指数”
Ppk= Process Performance K Ratio 可被译为“过程绩效K指数”
注:据有人说 这里的‘k’ 是 ‘centralizing facteur’⑥,可能是法语,即“居中因子”。
据此,Cp和Cpk被称为过程能力指数;而Pp和Ppk则被称为过程绩效指数。我们权且将过程能力指数和绩效指数统称为衡量过程能力的指标。
以上是关于Cp, Cpk, Pp 和 Ppk这些指标的定义。下面我们讨论这些指标的计算方法。
")
")
了解了这些概念和计算公式,下面让我们看看这些指数的共同点和区别。
4. Cp, Cpk, Pp 和 Ppk的异同点
4.1 Cp, Cpk, Pp 和 Ppk的共同点:
Cp, Cpk, Pp 和 Ppk都是用来测量过程能力的指标。它们的共同点是:
• 都被用来表示过程能够生产出达到可接受标准的产品的程度或能力
• 都被用来表示过程的产出品的离散程度和可接受标准的比率
• 它们的值越大,过程越能够更好地生产出达到可接受标准的产品
首先是有k指数(Cpk和Ppk)和没k指数(Cp和Pp)的区别:没k指数(Cp和Pp)只显示过程的产出品的离散程度和可接受标准的关系;而有k指数(Cpk和Ppk)除了显示过程的产出品的离散程度和可接受标准的关系外,还关注过程的产出品的均值是否偏离可接受标准的中间值。其数学关系是:有k指数永远不大于没k指数,即:
• Cpk≤Cp(当过程的产出品的均值和可接受标准的中间值重叠时,Cpk=Cp, 否则Cpk<Cp);
• Ppk≤Pp(当过程的产出品的均值和可接受标准的中间值重叠时,Ppk=Pp, 否则Ppk<Pp)。
我在工作中发现没K指数(Cp和Pp)应用得较少,估计是因为很少有过程的产出品的均值正好与可接受标准的中间值重叠。但其实这是不对的:有k指数(Cpk和Ppk)和没k指数(Cp和Pp)应该一起使用才能准确体现过程的能力,详情其后讨论。
现在让我们先看看过程能力指数(Cp和Cpk)和过程绩效指数(Pp和Ppk)的区别。
过程能力指数(Cp和Cpk)和过程绩效指数(Pp和Ppk)的区别,即Cp和Pp的区别,Cpk和Ppk的区别。
")
其中 R-bar是通过将被考量的过程在某一时段(考察区间)的产出品的观察样本的某个性能的数值制成过程控制图(Control Chart)来得到的;而d2 则是一个统计学常数,与过程控制图的样本亚组(subgroup)的样品个数有关,其值可以参考下表⑤。
")
d2的值可以通过很多书籍查到,但常用的就是n小于10的值。其实超过5的话数据量就很大了。
现在我们了解了S和 西格玛的区别,那么我们是不是就理解了Cpk和Ppk的区别了呢?似乎没那么简单。相信大家还是弄不清它们的本质区别。
下面我们用一个很容易理解的例子来说明一下它们的计算。
假设公司有班车接员工上班, 我们让坐班车的同事记录班车第一个站到公司的时间(分钟),观测了30天,得到下面表格的数据。
")
使用标准差公式计算,得出S=11.6。
假设公司要求司机每天要在从第一站到公司的时间要保持在55分钟到70分钟之间(时间太短司机可能超速,不安全,时间太长班车会晚点),则LSL=55,USL=70。套用以上的公式可以得到以下Pp和Ppk的结果。
")
")
")
根据这个控制图,得到 R-bar=12.7。
运用上面的公式 可以得到 西格玛=12.7/1.128=11.259。
再运用Cp和Cpk的公式得到:
Cp = 0.222, Cpk = 0.138
综上我们可以得到以下的结果:
Pp = 0.216 Ppk = 0.134;Cp = 0.222, Cpk = 0.138
大多数人可能都会得到这样的结果并就此打住。但是这里关于Cp和Cpk的计算存在很明显的错误,因为Cp和Cpk的计算是有两个必要条件的:
1. 过程是稳定的(处于统计受控状态)
2. 所观测的数据是呈正态分布的
没有这两个必要条件所计算出来的Cp和Cpk值是不具有统计学意义的,或者说所得到的Cp和Cpk不准确。
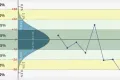
上图很明显地看出,这个过程是处在“非稳定或非可控”(not stable or not under control)状态,因为图中有1个点超出了控制上限(UCL)。根据Cp和Cpk的定义,该组数据中有特别原因造成的点,过程不稳定,因此不能直接用此控制图的数据来计算Cp和Cpk。这也是为什么不要用数学公式来直接计算 并计算Cp和Cpk的原因。为了得到稳定的过程控制图,需要把这个点去掉,再重新制图,得到下面的控制图。
")
请注意这个图还是有一个点是超出控制线的(R-图中的虚线的点),这个点也应该被去掉。去掉这个点,可以得到下面的控制图。
")
")
于是我们得到结果:
Cp = 0.330
Cpk = 0.193
可以看出实际的Cp和Cpk都有所增加。也就是说如果过程不稳定,计算出来的Cp和Cpk值会偏低,这就会低估过程的潜在能力。
根据定义,Pp和Ppk 的计算是不可以把这两个点去掉的。因此Pp和Ppk 是不需要重新计算的。这样针对这个例子中的数据,我们可以得到:
Pp = 0.216, Cp = 0.330;
Ppk = 0.134, Cpk = 0.193;
除了过程稳定,过程能力指数(Cp和Cpk)的计算还需要数据呈正态分布。那么这组数据是否符合正态分布呢?我们可以借助统计学工具来做分析,如下图。可以看出p>0.05,所以这组数据是成正态分布的。所以上面的计算是成立的。
")
值得注意的是数据是否成正态分布与过程是否稳定没有直接的关系。不稳定的过程的数据也可能是成正态分布的。
至此,该组数据(去掉两个点)通过了这两个测试:过程稳定和正态分布。因此上面的关于Cp和Cpk的计算是正确的。而用于Pp和Ppk计算的数据则不必进行这两个测试。
通过这个例子,可以将过程能力指数(Cp和Cpk)和过程绩效指数(Pp和Ppk)的区别总结如下:
1. 过程能力指数(Cp和Cpk)表示的是过程在稳定(即没有任何特殊原因或漂移干扰产出品的特性或者说是在可控(under control)的)状态下能使其产出品达到可接受标准 的程度的指标,也可以理解为过程的”潜在”能力。(注:”潜在”是相对目前的过程条件而言,改变过程条件可以不断提高Cp和Cpk,这就是不断改进(continuous improvement )的理念。因此将Cp和Cpk翻译成”过程潜能指数”和”过程潜能K指数”更为贴切。因为Cp和Cpk体现的是稳定状态下过程的潜在能力,因此Cp和Cpk可以用来预测该过程将来在现有过程条件下的最好的情况。
2. 过程绩效指数(Pp和Ppk)则是过程在过去某个观察时段内的实际绩效,即是该过程的已经产生的产出品实际达到可接受标准的情况。它们不考虑过程是否稳定,即便可能包括特殊原因(special cause)干扰产出品的特性或者说过程不一定处在一个可控的状态(out of control),同样可以计算出Pp和Ppk。由于Pp和Ppk是体现过程在过去的某个时段的绩效,所以Pp和Ppk被称为”过程绩效指数”。也正因如此,Pp和Ppk 仅代表过程过去的情况,并不能用来预测过程将来的状态(将来可能更好也可能更坏,当然也可能一样)。
许多作者反对使用过程绩效指数,因为它们没有统计学意义,而且认为是统计学在SPC–统计学过程控制中应用的倒退。有趣的是过程绩效指数(Pp和Ppk)是美国三大汽车公司为了对其供应商的绩效进行标准化而产生的,并且被纳入了美国ANSI标准。
笔者认为过程绩效指数(Pp和Ppk)的产生与其计算简单且没有太多的统计学限制有关。因为它们始终不会大于过程能力指数(Cp和Cpk),作为过程过去的业绩指标还是可以的。但是它们会低估过程的实际潜在能力,可能误导过程改进的方向。
3. 许多作者都认为过程能力指数(Cp和Cpk)是短期过程能力指标,而过程绩效指数(Pp和Ppk)是长期过程能力指标①②③⑥。但这个说法很容易被误解为Cp和Cpk是短时间收集的数据,而Pp和Ppk是长时间观测收集的数据。而实际上这里的”短期””长期”与采集数据的时间长短没有任何关系①,因为短期测试结果也可能存在由特殊原因引起的离散(variability),而长期收集的数据也可能没有特别原因引起的离散。其本质的区别是计算中是否允许有被特殊原因引起离散的数据:Pp和Ppk是将所有被观测的样本数据都用于标准方差的计算, 而用于计算Cp和Cpk的西格玛不应该包括由特殊原因引起离散的数据。
综上,我们可以将过程能力指数(Cp和Cpk)及过程绩效指数(Pp和Ppk)的本质区别总结如下:过程绩效指数(Pp和Ppk)是过程的过去或现实;而过程能力指数(Cp和Cpk)是过程的潜能或将来。过程能力指数的计算必须满足”过程稳定”和”数据正态分布”两个必要条件;而用于Pp和Ppk计算的数据则不必进行这两个测试。过程能力指数及过程绩效指数的数学关系是:Cp≥Pp , Cpk≥Ppk。当过程稳定(stable或under control)且数据呈正态分布时Cp=Pp,Cpk=Ppk(注意这里的”=”是统计学意义上的相同);只要有特殊原因存在, Cp>Pp , Cpk>Ppk。理解这一点对它们的应用很关键。
5. Cp,Pp ,Cpk和Ppk的应用
首先了解过程能力指数和过程绩效指数的区别可以帮助理解在什么情况下采用哪个指标。通常要知道过程的实际绩效情况,即过程实际的产出品满足可接受标准的情况,应该采用过程绩效指数。如果想知道目前的过程是否已经是达到了稳定的潜在状态时,可以比较过程能力指数和过程绩效指数的差别,即Cp和Pp, Cpk和Ppk的差别:二者差别越小,说明目前的过程的绩效越接近稳定状态,即过程不存在太多的特殊原因引起的偏离(variation)。如果差异很大,则说明过程不稳定,需要找出那些特别的原因,消除这些原因,过程即可被改进。管理者也可以利用过程能力指数和过程绩效指数的差别,制订不断改进的目标。例如上面的例子Ppk=0.134, Cpk=0.193。目标可以是让Ppk达到0.193.
了解了有K和没K的区别可以帮助公司判断过程的产出品是否偏离可接受标准的中间值。如果Pp和Ppk比较,Cp和Cpk比较,相差不大,说明过程的产出品的特性均值没有偏离可接受标准的中间值太多。要提高Ppk或Cpk的值,只能减少点间差或样品亚组内最大和最小值的差异,即降低过程的标准方差(S或 西格玛)。如果Pp和Ppk比较,Cp和Cpk比较,相差很大,那么将过程的产出品的特性的均值调整到可接受标准的中间值,就会很有效地提高Ppk和Cpk值,使过程能更好地满足可接受标准的要求。当然这也可以通过计算样本的均值,并和可接受标准的中间值比较来完成。
另外,过程能力指数和过程绩效指数可以被用来衡量供应商的业绩。如果可接受标准是一样的,当然指数越大的供应商越好。
")
值得注意的是经典的作者都没有将过程绩效指数(Pp和Ppk)作为考量过程是否能达标的指标,因为绩效指数的计算没有考虑过程是否稳定,而没有稳定性就没有过程能力可言。
6. 总结
过程能力是指过程离散度的6西格玛宽度,与其产出品的可接受标准无关。如果过程的产出品的数据是呈正态分布的,那么99.73%的数据会落在这个6西格玛的宽度内。
常用的衡量过程能力的指标有过程能力指数(Cp和Cpk)和过程绩效指数(Pp和Ppk)。没k指数(Cp和Pp)只显示过程的产出品的离散程度和可接受标准的关系;而有k指数(Cpk和Ppk)除了显示过程的产出品的离散程度和可接受标准的关系外,还关注过程的产出品的均值是否偏离可接受标准的中间值,其数学关系是:Cpk≤Cp;Ppk≤Pp。
过程能力指数(Cp和Cpk)和过程绩效指数(Pp和Ppk)的主要区别是:
1)过程能力指数Cp和Cpk)的计算需要满足两个条件–过程稳定且数据呈正态分布,而过程绩效指数(Pp和Ppk)的计算则不需要考虑这两个条件。
")
过程能力指数(Cp和Cpk)是具有统计学意义的指数,表示的是过程的“潜能”,可以用来预测过程的将来,而过程绩效指数(Pp和Ppk)的统计学意义并不被专家们接受,并且不能被用来有效地预测过程的未来。









 透彻理解卡方检验 - 汽车质量管理笔记
[…] 化简后的式子是我们在卡方检验中需要用到的式子,所以请大家牢记!对于上述式子有疑惑的读者可以学习基础的概率论,也可以参考我之前写的一篇关于独立的文章(《【直观数学】如何理解两事件间的独立关系》)。如果没有问题的话,我们可以进入到卡方检验原理与步骤的主体介绍部分! […]
透彻理解卡方检验 - 汽车质量管理笔记
[…] 化简后的式子是我们在卡方检验中需要用到的式子,所以请大家牢记!对于上述式子有疑惑的读者可以学习基础的概率论,也可以参考我之前写的一篇关于独立的文章(《【直观数学】如何理解两事件间的独立关系》)。如果没有问题的话,我们可以进入到卡方检验原理与步骤的主体介绍部分! […]
 infinite cui
需求VDA6.3 表格,谢谢
infinite cui
需求VDA6.3 表格,谢谢
 大师兄
说的挺有道理的,从现实看到的大部分情况,做技术的人都比较直,对技术的一丝不苟,容易在遇到需要展现管理能力的时候,就会表现出短板来。管理需要授权,更多应该思考团队、部门间,人员发展,对未来的变化做出应对等的能力。
大师兄
说的挺有道理的,从现实看到的大部分情况,做技术的人都比较直,对技术的一丝不苟,容易在遇到需要展现管理能力的时候,就会表现出短板来。管理需要授权,更多应该思考团队、部门间,人员发展,对未来的变化做出应对等的能力。
 john
如何获得这个PPT文件
john
如何获得这个PPT文件